HashMap
数据结构、算法

1. HashMap出现的背景
这一部分,先从数组和链表的优劣势,来引出散列表和哈希。看一下散列表和哈希相对于前两种,有哪些特点。
1.1 数组的优势劣势
先看看数组的内存结构图。

看这个图,应该很清晰的看到数组的特点和优劣势。
- 数组的特点是顺序存储,长度的固定长度
- 数组中查找数据非常方便,可以直接根据索引读取到固定位置的数据 (优势)
- 数组增加删除数据非常麻烦,需要先对数组进行扩容,然后重新对数组进行赋值 (劣势)
1.2 链表的优势劣势
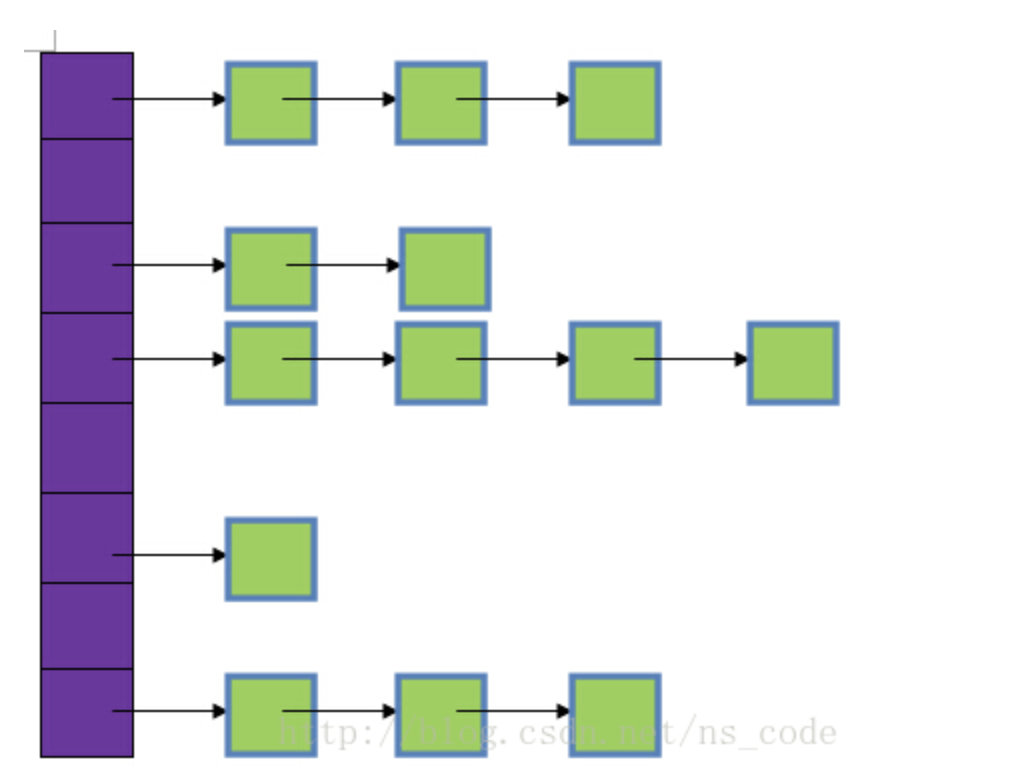
来看看链表的内存结构图。链表也很多种啊,单向,双向,循环等等,我们拿单链表来说。

上面两张图,第一张是链表的内存结构图,可以看到,链表的结构是有一个数据区和地址区,地址区是依次指向下一个元素。链表的插入和删除操作也非常方便,只用将上一个的地址指向要插入的元素就可以了。所以从链表中我们也可以得到如下的特点。
- 链表的长度不是固定的,可以根据需要动态的调整
- 链表的查找会非常麻烦,不能根据索引查找,需要一个个从头到尾去遍历 (劣势)
- 链表的插入和删除操作非常方便 (优势)
1.3 散列表和哈希
说了这么多,列举了前面两种数据结构的优劣势,有没有一种数据结构可以同时兼具以上两种的优点呢,这个就要说到散列表了。
来看看散列表的结构。
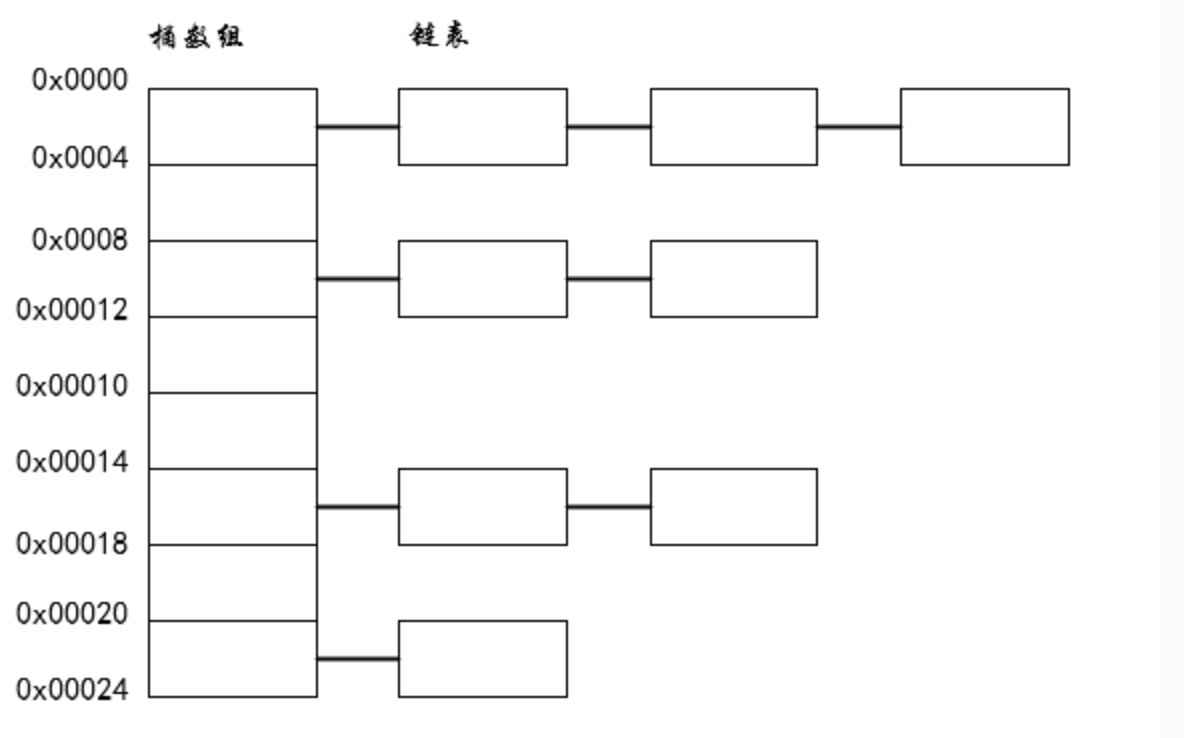
这个就是散列表的内存结构图。可以看一下,分为两部分,左边的紫色部分是一个数组结构,每一个数组中都有一个链表的头指针,右边的绿色部分是一个链表结构,用来解决冲突问题。散列表是集成了数组和链表两种数据结构的特点。
Hash,是一种算法,它的原理是,把任意长度的输入都转算成固定长度的输出。这个映射的方法就是Hash算法。Hash算法有如下的特点:
- 不能进行反向的推导。就是指不能根据结果来推导出原始的数据
- 任意微小的原数据的改变都会得到一个不同的结果
- Hash算法的执行效率非常高
- Hash算法有冲突概率。因为输入空间要远大于输出空间,所以可能会存在不同的输入得到相同的输出问题
2. HashMap原理
2.1 HashMap 的物理结构
前面讲了这么多,HashMap就可以很容易理解了,就是用Hash算法实现的一个散列表。看下图。
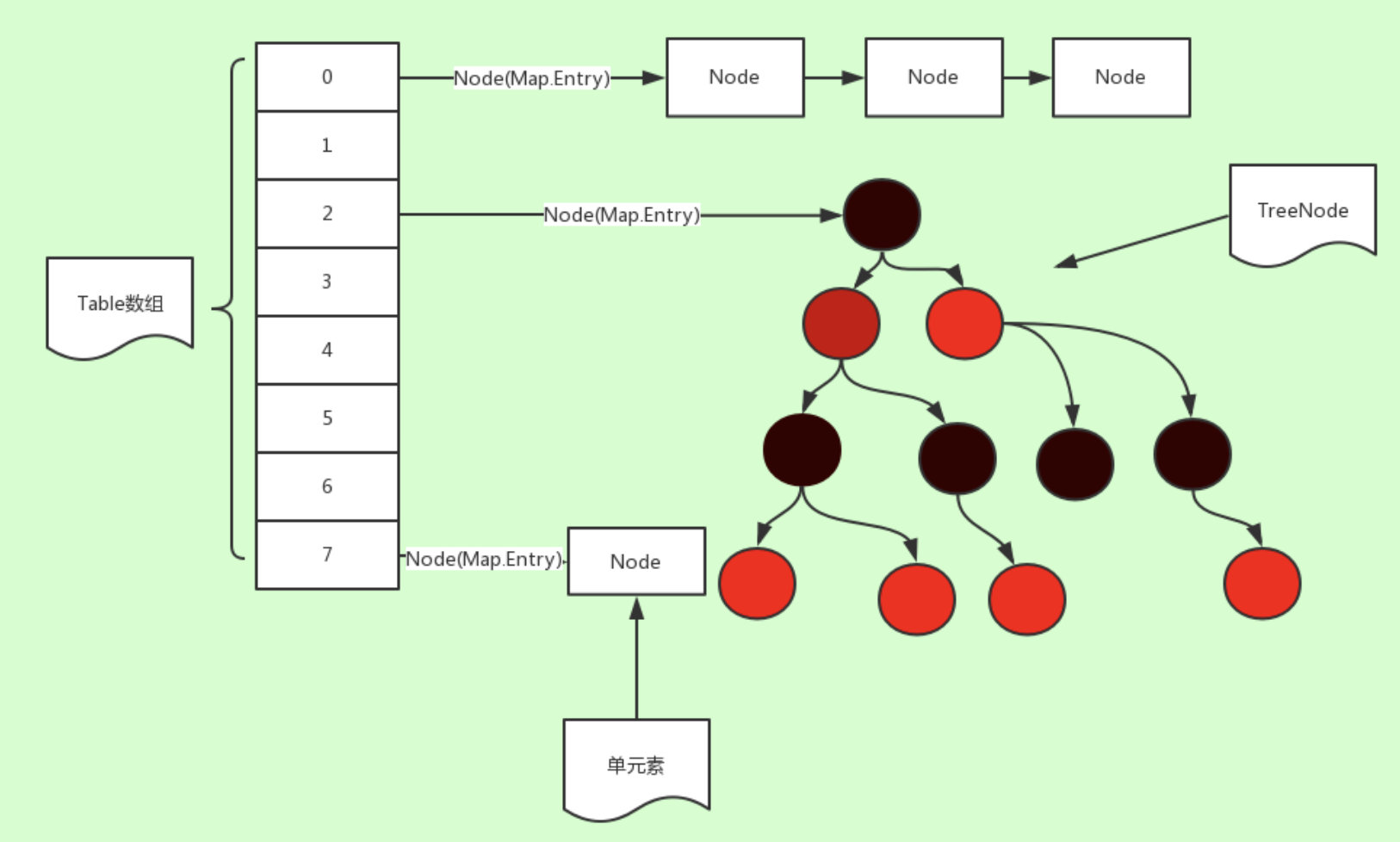
就是数组+链表+红黑树结构。
链表是当有冲突元素时会在数组结构中加上链表。
当链表节点数量大于等于8个,而且哈希表的所有元素个数大于64个时,会把链表结构升级为红黑树结构。
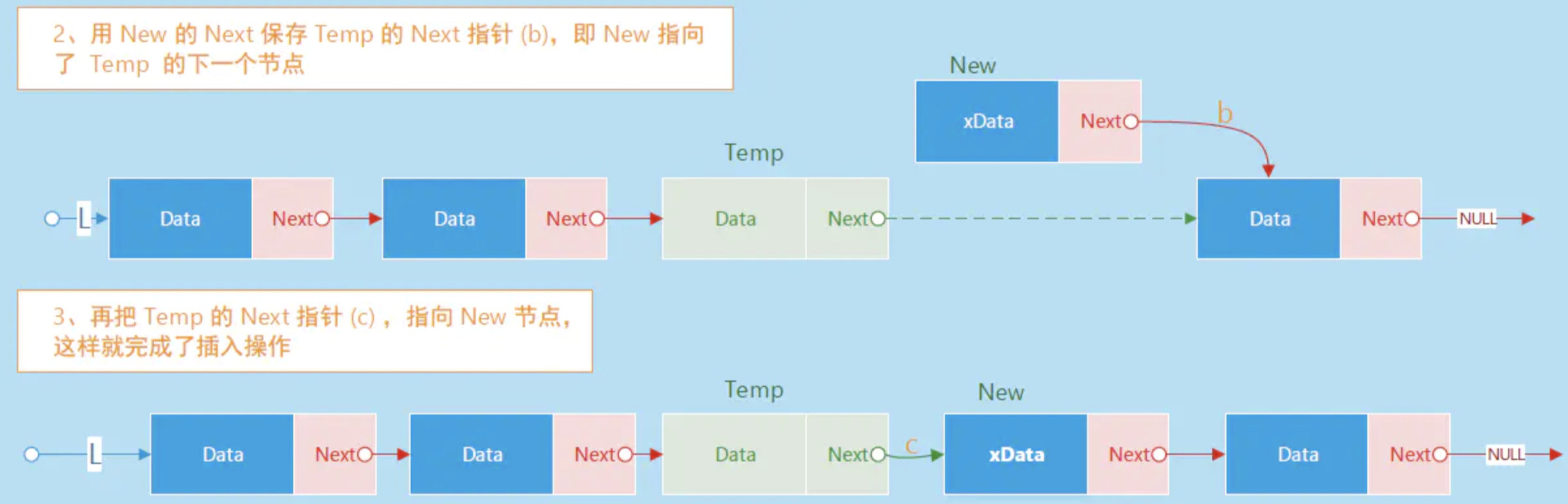
2.1 HashMap的插入数据流程
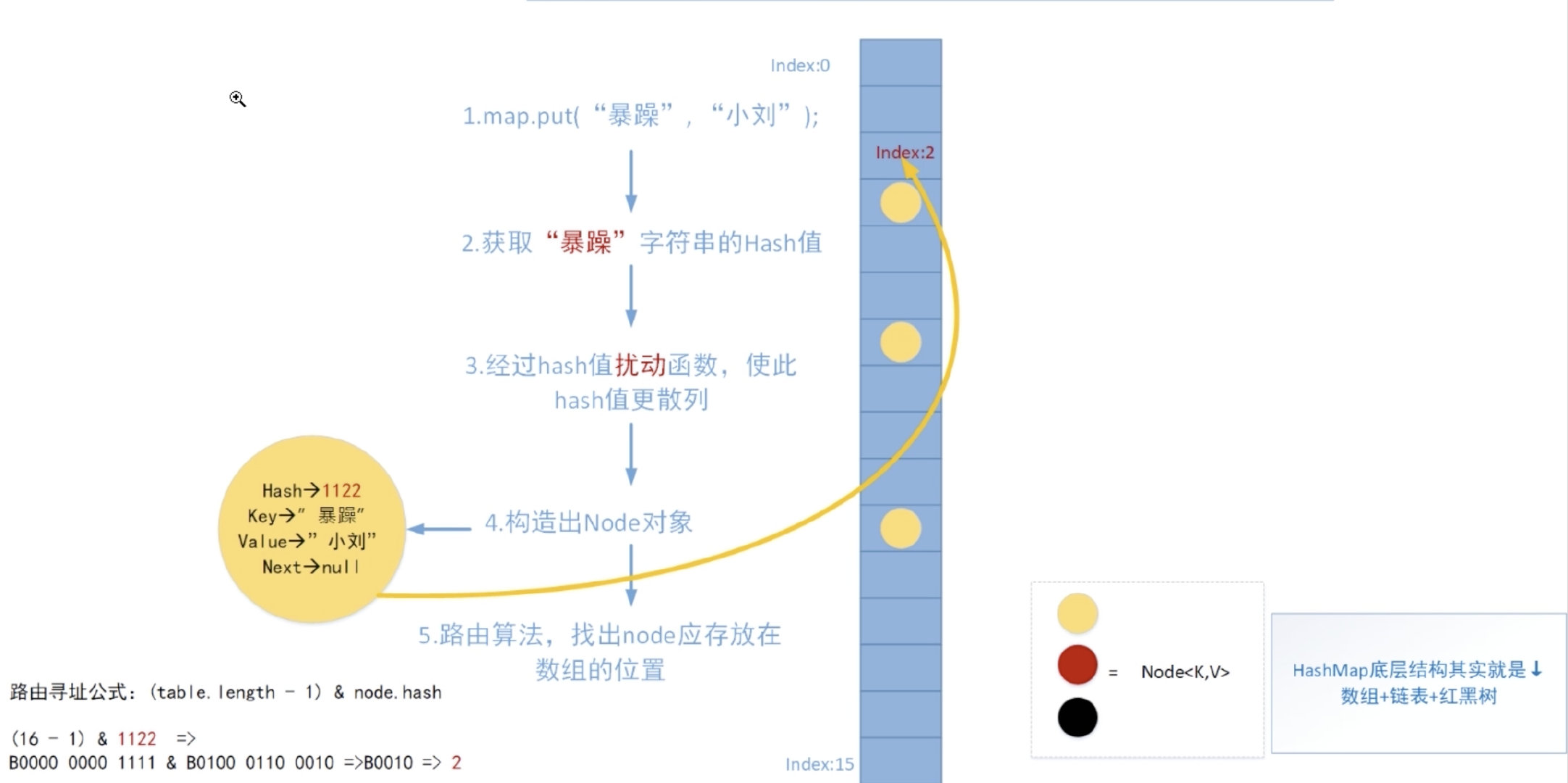
可以看下这张图,这个流程就是数据插入到HashMap的流程。
首先是讲插入的key通过hash算法转成hash值,然后hash值通过扰动函数,使hash值更加的散列,之后在构造出hash的node节点,再根据路由算法,计算这个node节点应该插入到哪个位置。
可以看下这个路由公式,table length是hash数组的长度,一般是2的次方,然后再和hash值进行与元素,得到插入的位置,将这个node插入到hashmap的节点。
2.2 Hash碰撞
前面也讲过了,当两个不同的输入得到了一个相同的hash值,或者根据路由公式,计算出的node节点位置有冲突时,也会引起Hash碰撞。发生Hash碰撞后,会在数组节点形成一个链式表。
2.3 Hash扩容
可以看到,如果Hash数组的大小有限时,会很容易造成Hash碰撞。发生Hash碰撞后,链表的长度就会越来越长,导致的结果就是无法发挥出HashMap的优势,就往链表上靠了。所以为了解决这个问题,就要对Hash进行扩容。扩容后,可以有效的减少碰撞。
3. HashMap源代码分析
3.1 C++ Key-Value 形式的容器
JAVA 的HashMap是用的JDK。 C++ 有很多的key-value形式的容器,map / hash_map / unordered_map / vector_map.
Map,是用的红黑树实现,构建map花费的时间比较长。
vector_map 在c++中没有实现,基本思想就是使用vector保存数据,插入完成后进行排序,然后使用二分查找。
hash_map,STL的实现叫做unordered_map, 都是基于hash_table实现的,首先是分配一大片内存,形成很多桶,利用hash函数将key映射到不同的桶中。
hash_map的查找速度比map快,它的查找速度与数据量大小无关,属于常数级别。map的查找速度是log(n)级别。