二、The use of Kubernetes and Docker
Kubernetes in action reading notes

1. Understanding Docker images, file systems and containers
The image of the container is a file after packaging and compiling the container. The packaging image depends on the Dockerfile file. The From line defines the starting content of the image, which is the basic image for construction. The process of building the image is to upload the entire directory of files to the Docker guardian During the process, Docker will first pull the basic image from the basic image warehouse, and then the packaging of the image is a layered structure, with the basic image as a layer, and then each command will be used as a new layer, layer by layer , the whole is a joint file system.
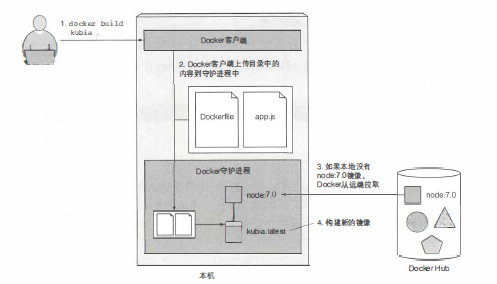
The understanding of the container, the container is actually an instance of the image running. The container runs on the operating system of the host, so there will be a problem, such as an image packaged on the RedHat host, can this image run on ubuntu? Not necessarily, it depends on whether you use something specific to the host, but you are running something that is not available on another host. The container running from the image is equivalent to a process on the host machine. The file system between each container is also independent.
2. Kubernetes cluster and Mini Kube
Let’s first understand the concept of a cluster. What is a cluster? A cluster is a combination of multiple computer nodes to form a cluster, so the advantages of the cluster are also obvious, which can better manage the system and provide the performance of a stand-alone system.
Take a look at mini kube, it is a local single-node cluster, it is not suitable for multi-node situations. To interact with kubernetes, you also need the kubernetes cli client.
Overview of multi-node Kubernetes clusters:
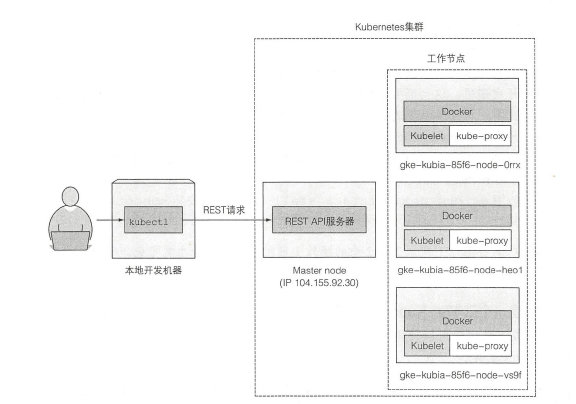
A kubernetes diagram of three nodes. Take a look at this thing, each working node has Docker, Kubelet and Kube-proxy, and you can use kubectl to send control commands to the master node through rest to control each sub-node. interesting.
3. ReplicationController
POD is the smallest unit controlled by Kubernetes. Kubernetes does not care about container scheduling, it only manages POD. There can be many containers in a POD, but this group of containers is closely related because they can be regarded as running on the same host. So what is ReplicationControler, and what is it used for.
According to my understanding, ReplicationControler is used to manage the horizontal expansion of POD, which can ensure that the specified number of POD can operate normally according to the setting.
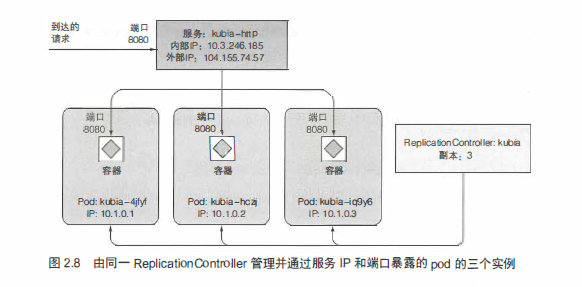
You can look at this picture, after external access, it will only be mapped to an internal ip, and then we don’t care which POD is called, because each POD inside is an independent ip. ReplicationControler to control the number of copies.
4. Sort out some related commands of kubectl
kubectl get pods, list all PODs, kubectl expose kubia –type=LoadBalancer –name kubia-http. Set the service network to LoadBalancer mode, kubectl get service, list all services
kubectl get replicationcontrollers, lists all replicas. kubectl scale rc kubia –replicas=3, expand the replica.
kubectl get rc, check capacity expansion. kubectl get pods -o wide, to view the ip of the POD and the running nodes. kubectl describe pod, you can view the log information of this POD.