HashMap
Data Structures, Algorithms

1. The background of HashMap
In this part, we first introduce hash tables and hashes from the advantages and disadvantages of arrays and linked lists. Take a look at the characteristics of hash tables and hashes compared to the first two.
1.1 Advantages and disadvantages of arrays
First look at the memory structure diagram of the array.

Looking at this picture, you should clearly see the characteristics, advantages and disadvantages of the array.
- Arrays are characterized by sequential storage and a fixed length of length
- It is very convenient to find data in the array, you can directly read the data at a fixed position according to the index (advantage)
- It is very troublesome to add and delete data in the array, you need to expand the array first, and then reassign the array (disadvantage)
1.2 Advantages and disadvantages of linked list
Let’s take a look at the memory structure diagram of the linked list. There are also many kinds of linked lists, one-way, two-way, circular, etc. Let’s take a single linked list as an example.

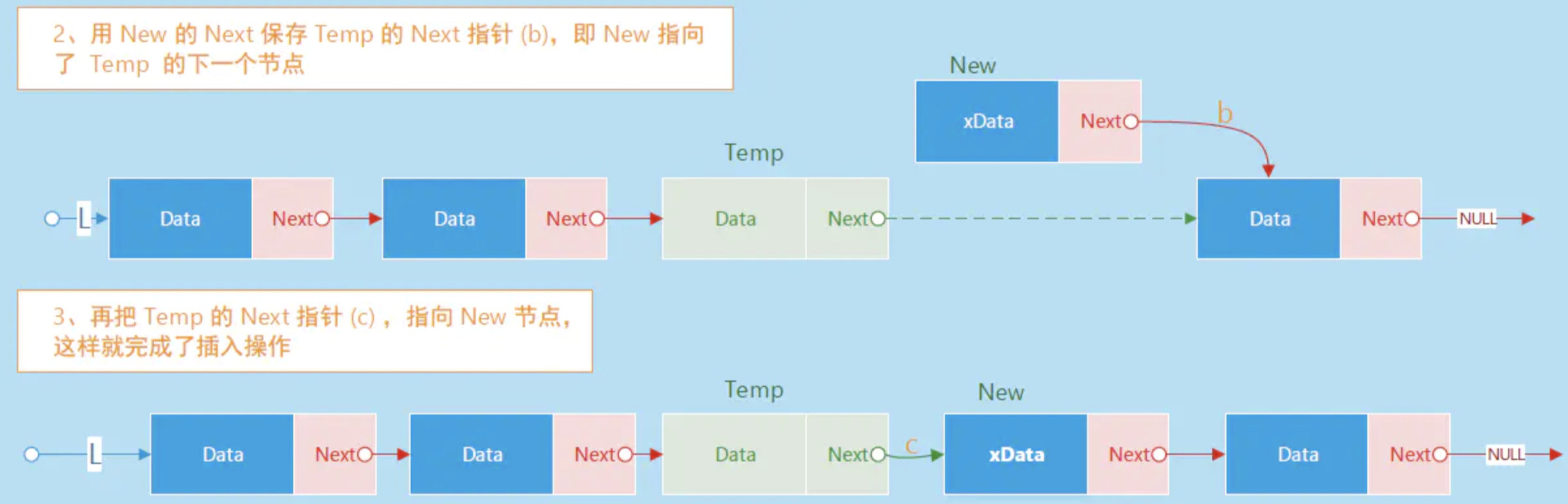
In the above two pictures, the first one is the memory structure diagram of the linked list. It can be seen that the structure of the linked list has a data area and an address area, and the address area points to the next element in turn. The insertion and deletion operations of the linked list are also very convenient, just point the address of the previous one to the element to be inserted. So from the linked list we can also get the following characteristics.
- The length of the linked list is not fixed and can be dynamically adjusted as needed
- The search of the linked list will be very troublesome, it cannot be searched according to the index, and it needs to be traversed from beginning to end one by one (disadvantage)
- The insertion and deletion operations of the linked list are very convenient (advantage)
1.3 Hash tables and hashes
Having said so much, I have listed the advantages and disadvantages of the first two data structures. Is there a data structure that can combine the advantages of the above two at the same time? This is about the hash table.
Let’s take a look at the structure of the hash table.
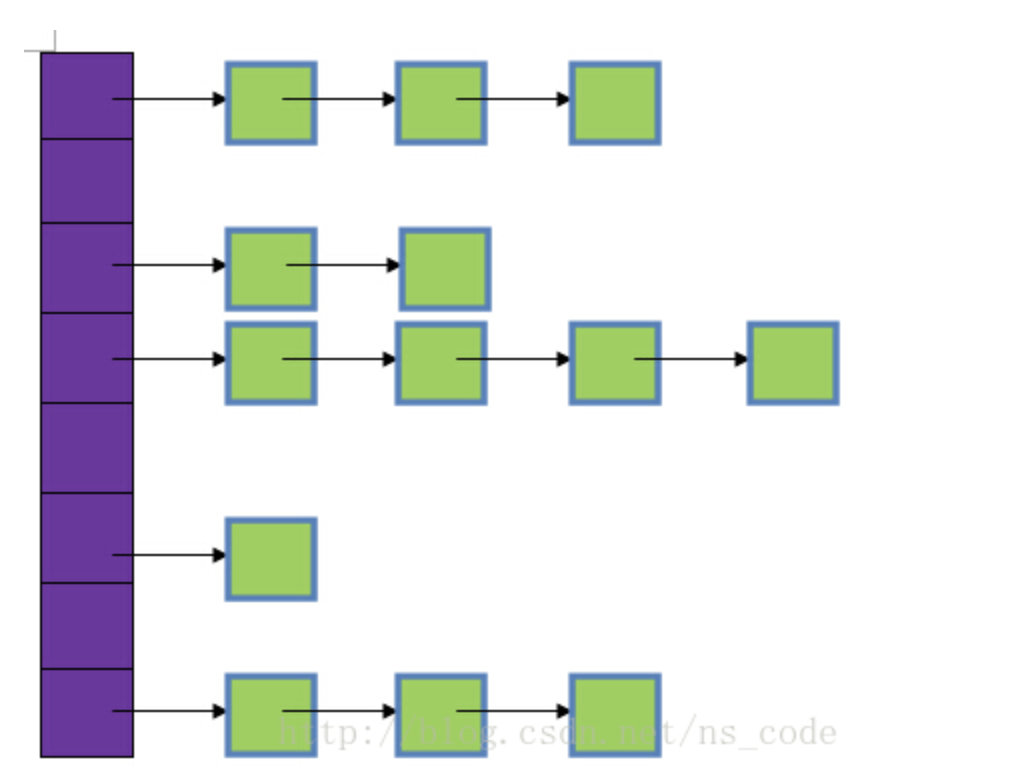
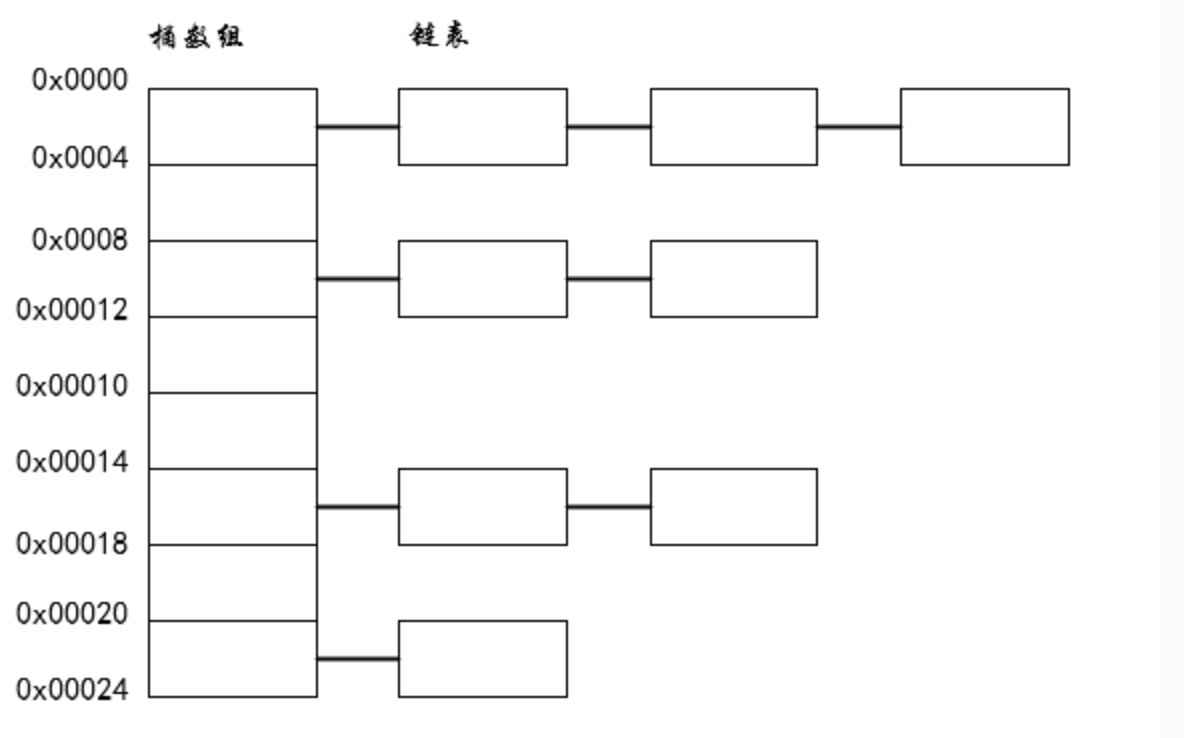
This is the memory structure diagram of the hash table. You can take a look, it is divided into two parts, the purple part on the left is an array structure, each array has a head pointer of a linked list, and the green part on the right is a linked list structure, which is used to resolve conflicts. The hash table is a feature that integrates the two data structures of arrays and linked lists.
Hash is an algorithm whose principle is to convert an input of any length into a fixed-length output. The method of this mapping is the Hash algorithm. The Hash algorithm has the following characteristics:
- No reverse derivation is possible. It means that the original data cannot be deduced from the results
- Any minor change to the original data will result in a different result
- The execution efficiency of the Hash algorithm is very high
- Hash algorithm has collision probability. Because the input space is much larger than the output space, there may be different input to get the same output problem
2. HashMap principle
2.1 Physical structure of HashMap
Having said so much earlier, HashMap can be easily understood, which is a hash table implemented by the Hash algorithm. See the picture below.
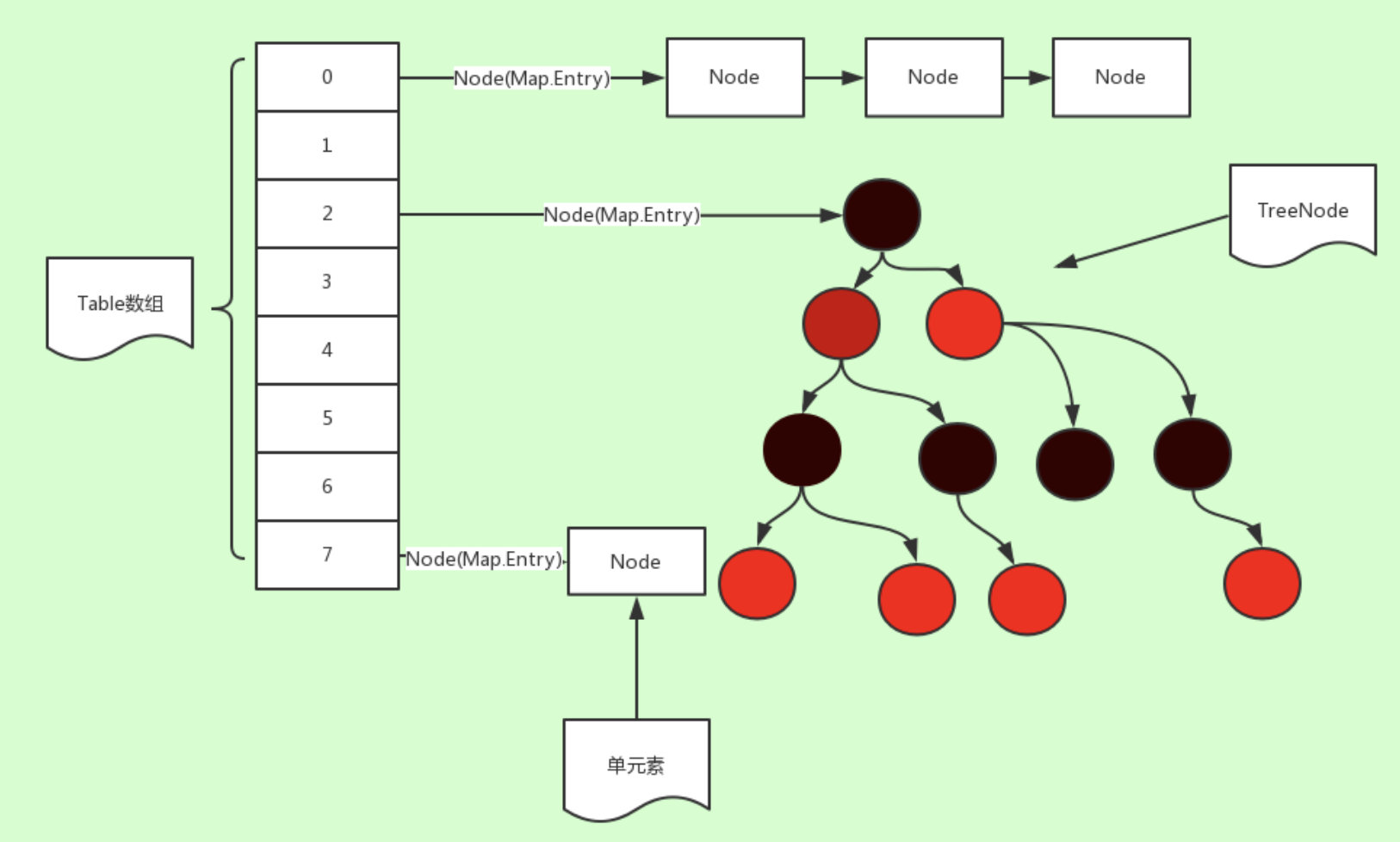
It is array + linked list + red-black tree structure.
The linked list is a linked list added to the array structure when there are conflicting elements.
When the number of linked list nodes is greater than or equal to 8, and the number of all elements in the hash table is greater than 64, the linked list structure will be upgraded to a red-black tree structure.
2.1 HashMap insert data process
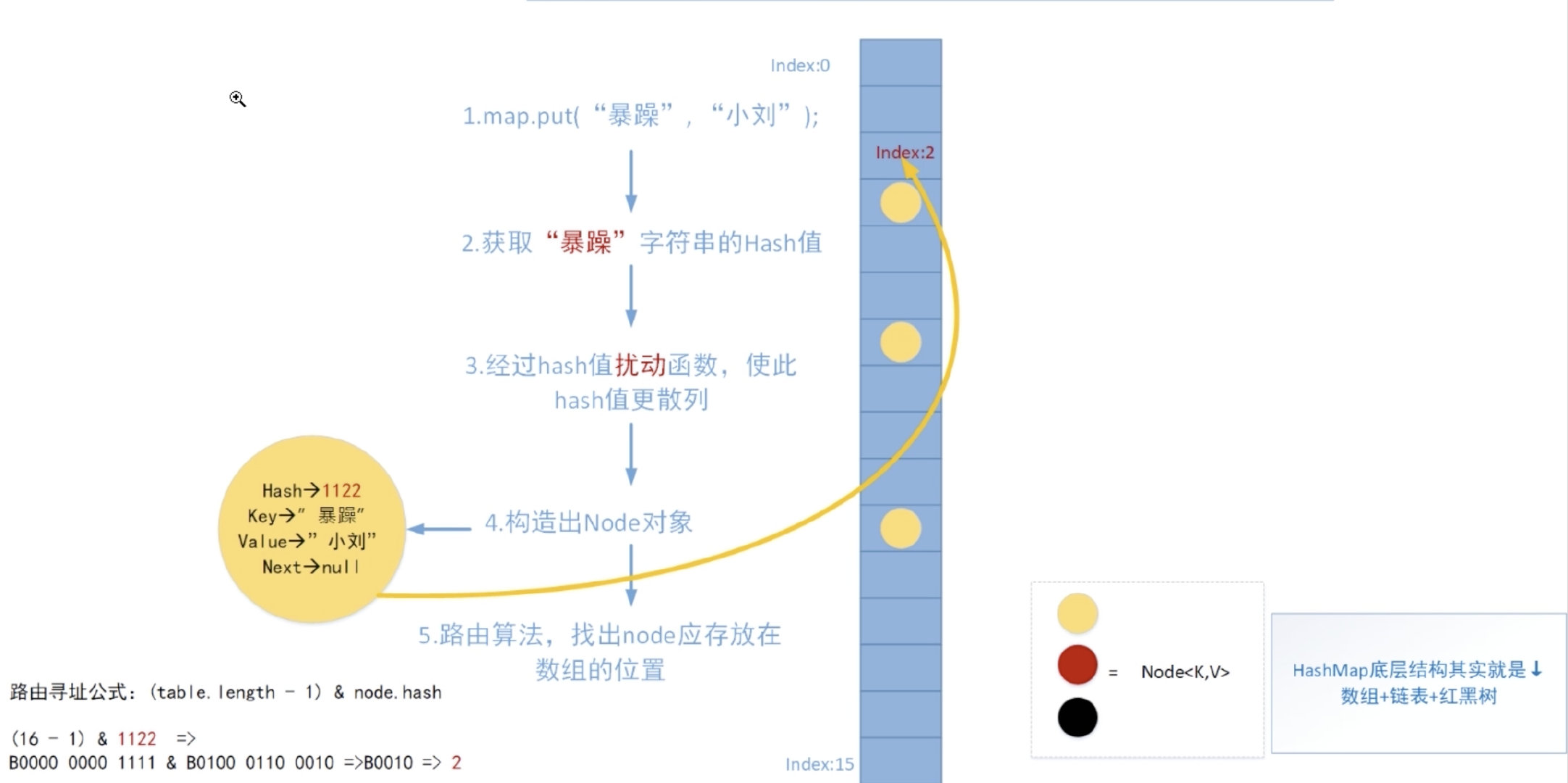
You can look at this picture, this process is the process of inserting data into HashMap.
First of all, the inserted key is converted into a hash value through the hash algorithm, and then the hash value is passed through the disturbance function to make the hash value more hashed, and then the node node of the hash is constructed, and then according to the routing algorithm, it is calculated that the node node should be inserted into which location.
You can look at this routing formula, table length is the length of the hash array, generally the power of 2, and then element with the hash value to get the insertion position, and insert this node into the node of the hashmap.
2.2 Hash collision
As mentioned earlier, when two different inputs get the same hash value, or when there is a conflict in the calculated node position according to the routing formula, a Hash collision will also occur. After a Hash collision occurs, a linked list will be formed at the array nodes.
2.3 Hash Expansion
It can be seen that if the size of the Hash array is limited, Hash collisions will easily occur. After a Hash collision occurs, the length of the linked list will become longer and longer. As a result, the advantages of HashMap cannot be used, and the linked list will be relied on. So in order to solve this problem, it is necessary to expand the Hash. After expansion, collisions can be effectively reduced.
3. HashMap source code analysis
3.1 C++ Key-Value container
JAVA’s HashMap uses JDK. C++ has many key-value containers, map / hash_map / unordered_map / vector_map.
Map is implemented with a red-black tree, and it takes a long time to build a map.
vector_map is not implemented in c++. The basic idea is to use vector to save data, sort after insertion, and then use binary search.
The implementation of hash_map and STL is called unordered_map, which are all implemented based on hash_table. First, a large area of memory is allocated to form many buckets, and the keys are mapped to different buckets using the hash function.
The search speed of hash_map is faster than that of map, and its search speed has nothing to do with the size of the data, which belongs to the constant level. The search speed of map is log(n) level.