A tragedy caused by iNode, I finally understood iNode for four hours.
Daily operation and maintenance experience

1 Background
Once when changing the program package, the program package has been updated to the latest version, and the process needs to be restarted, but the restart has been unsuccessful. Checking the startup error log, it was found that the creation of the file had been unsuccessful. At that time, the thought was that the machine disk might be full. After checking the disk usage, it was found to be normal, and I was stunned instantly. I couldn’t think of what the problem was. It suddenly occurred to me that I had learned about the inode in the Linux system before, and the Chinese translation is: index node. Each file created has an inode, which is used to record the basic information of the file. The resources of this node are also limited. I checked it immediately and found that the inode has been occupied by 100%. This is over, clean it up immediately. problem solved. Let’s talk about this in this article.
2 Understanding of iNode
2.1 Disk storage
To understand iNode, you first need to know some knowledge of Linux disk storage. The smallest storage unit of a Linux disk is a sector, which is a sector. Generally, the size of a sector is 512 bytes. When the operating system reads data, it does not read data in units of sectors, which is too slow, but reads in blocks Take, that is, block, a block will have multiple sectors, generally a block is 4KB, 8 sectors. These 8 sectors are continuous. The command to manipulate disks is fdisk.
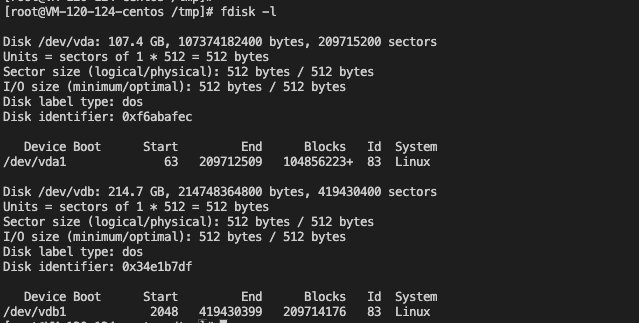
You can see the disk partition, partition size, sector, block and other related information. okay, having said so much, in fact, one piece of information that needs to be known is that the smallest unit of file storage is block, so what does this have to do with iNode?
2.2 Contents of iNode
Let’s take a look at the information stored in the iNode first.
I just open a file to see the iNode information of this file:

|
|
Looking at the content of this iNode, it is not difficult to understand the role of iNode. It can be understood that the operating system assigns an iNode node to each file created, that is, each file and the iNode number are in a map relationship, and the iNode number is the key when storing. When it is necessary to operate the file, it is divided into three steps: **1) Find the iNode node number through the file name. 2) Obtain the entire iNode information through the iNode node number. 3) Find the Block to which the file belongs according to the iNode information, and read out the data. ** You can see the iNode number of the file through ls -i.

2.2 iNode size
iNode will also consume hard disk space. After the hard disk is formatted, it will be divided into two areas, one is the data area, which stores file data; the other is the iNode area, which is used to store the information contained in the iNode. The size of each iNode is generally 128 bytes or 256 bytes, you can use the dumpe2fs command to check the iNode size.

At the same time, the number of iNode nodes allocated by the system is limited, so it is very likely that the iNode nodes will be used up. After the iNode nodes are used up, new files cannot be created on the hard disk. So what happened at the beginning of the article. About how to clean up the iNode after writing, see the description in the following article.
2.4 iNode meaning summary
Through the introduction, we can see the Linux design philosophy of iNode, everything in Linux is a file, and the identification of the file is iNode, so the file name is not important for the Linux system, what is important is the unique iNode, with the iNode node number , you can accurately find all the files in Linux.
3 Extension of iNode
3.1 Directory file permissions
The files are all in the directory. In the Linux system, the directory is also a kind of file. Opening the directory is actually opening the file in the directory. The directory file is a collection of file names and iNode node information under the directory.
 The iNode node that reads the file needs to execute the permission. Through this, it is easy to understand the relationship between the directory permission and the file permission.
If the directory does not have execution permission, basically nothing can be done, and some information of the files under the directory cannot be read. Execution permission is very important for directory permissions.
The iNode node that reads the file needs to execute the permission. Through this, it is easy to understand the relationship between the directory permission and the file permission.
If the directory does not have execution permission, basically nothing can be done, and some information of the files under the directory cannot be read. Execution permission is very important for directory permissions.

Except for root privileges, root privileges are basically superman, wearing underwear outside, and will not be affected in any way.
3.2 Hard link
With the understanding of iNode, it is easier to understand and use some links in Linux.
As mentioned above, generally a file name and an iNode number have a one-to-one correspondence, but multiple identical file names can also correspond to an iNode number. In this way, different file names can be used to access the same content. Modifying the file content will affect all files pointing to this iNode; but deleting a file or file will not affect another file’s access to this iNode. This is the hard link that is used a lot.
After mastering the iNode, it is easier to understand the hard link. The actual content of the file is only related to the iNode node, and has nothing to do with the file name.

I created a hard link to test.txt, and you can see that the iNode values of the two files are the same. You can also see that the number of links is 2. If one of the files is deleted, the number of links will be reduced by 1, and the iNode number will be recycled when it reaches 0.
Here is the iNode of the directory. After the directory is created, two directories will be generated by default: ‘.’ and ‘..’. The iNode number of the former is the iNode number of the current directory, and the iNode number of the latter is the iNode number of the parent directory of the current directory.
3.3 Soft link
There is also a soft link, also called a symbolic link, which means that the iNodes of the two files A and B are different, but the content of file A is the path of file B, and the system will automatically point the access to B, so no matter which file is opened, File B that is both operational.

So file A depends on file B. If file B is deleted, file A will not be opened. The difference between this and the hard link is that file A points to the file name of file B, not the iNode number of file B.
4 Solution to iNode resource exhaustion
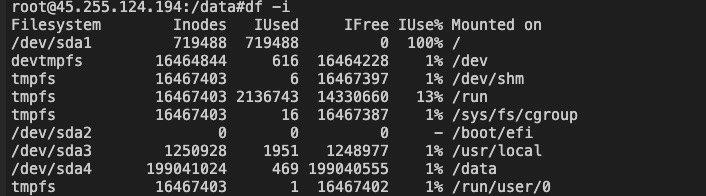
Back to the question at the beginning of the article, through df -i, my iNode usage is already 100%, how to solve it? The basic idea is to find the path of the file handle. Generally, if the iNode is exhausted, there must be a process or task that has been creating files, resulting in exhaustion.
- View the directory with the most files
|
|
If you determine which directory, you can /* write specific points.
- Delete a large number of files
|
|
Just delete it, use the xargs command.
Avoid this mass creation of files after you find the problem.